
1. Q-learning이란?
Q-learning은 각 상태에서 어떤 행동이 얼마나 좋은지를 점수(Q-value)로 학습하는 강화학습 알고리즘입니다.
에이전트는 환경과 상호작용하면서 행동을 해 보고, 받은 보상을 바탕으로 행동의 점수를 조금씩 수정합니다.
이 과정을 반복하면:
- 좋은 행동의 Q값은 점점 커지고
- 좋지 않은 행동의 Q값은 점점 작아지면서
- 결국 에이전트는 각 상태에서 Q값이 가장 큰 행동을 선택하게 됩니다.
그래서 Q-learning은 대표적인 가치 기반(Value-Based) 강화학습 알고리즘으로 많이 소개됩니다.
2. Q값(Q-value)이란?
Q-learning에서 가장 중요한 개념은 Q값(Q-value)입니다.
Q(s, a)- s: 현재 상태(State)
- a: 행동(Action)
현재 상태 s에서 행동 a를 했을 때, 앞으로 받을 것으로 기대되는 보상
상태가 “이 위치가 얼마나 좋은가?”라면, Q값은
“이 위치에서 이 행동을 했을 때 얼마나 좋은가?”를 나타낸다고 보면 됩니다.
3. Q-learning이 작동하는 흐름
Q-learning의 기본 흐름은 다음과 같습니다.
- 현재 상태를 본다.
- 가능한 행동 중 하나를 선택한다.
- 그 행동을 실행한다.
- 환경으로부터 보상 r을 받는다.
- 다음 상태로 이동한다.
- 방금 한 행동의 Q값을 수정한다.
위 과정을 계속 반복하면서, 에이전트는 점점 더 “좋은 행동”을 학습하게 됩니다.
4. Q-learning의 핵심 수식
Q-learning에서 Q값을 업데이트할 때 핵심은 아래 한 줄입니다.

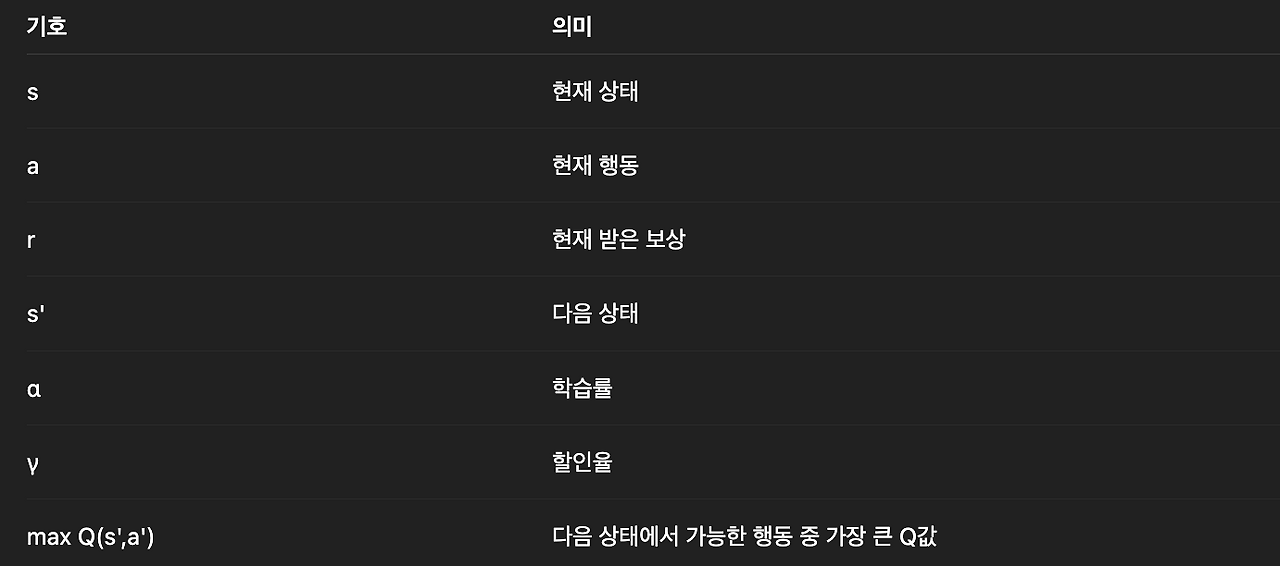
Q(s, a) ← Q(s, a) + α [ r + γ maxₐ′ Q(s′, a′) − Q(s, a) ]- α (alpha): 학습률 – 얼마나 크게 수정할지
- r: 현재 스텝에서 받은 보상
- γ (gamma): 할인율 (미래 보상을 얼마나 중요하게 볼지)
- s′: 다음 상태
- maxₐ′ Q(s′, a′): 다음 상태에서 가능한 행동들 중 가장 큰 Q값(최대 미래 가치)
한 줄로 요약하면:
현재 행동의 가치를
“현재 보상 + 다음 상태의 최대 미래 가치”를 이용해서 조금씩 수정하는 과정
괄호 안의r + γ maxₐ′ Q(s′, a′) − Q(s, a)
부분이 바로 TD Error(현재 추정이 얼마나 틀렸는지)입니다.
5. 1차원 예제 – S → G 직선 이동
아주 단순한 1차원 환경을 예로 들어 보겠습니다.
S . . . G
0 1 2 3 4- 설정
- 시작 상태:
0(S) - 목표 상태:
4(G) - 목표 도착 보상:
+10 - 그 외 이동 보상:
-1
- 시작 상태:
- 행동
left(왼쪽으로 한 칸)right(오른쪽으로 한 칸)
처음에는 모든 Q값을 0이라고 가정합니다.

Q = {
0: {'left': 0.0, 'right': 0.0},
1: {'left': 0.0, 'right': 0.0},
2: {'left': 0.0, 'right': 0.0},
3: {'left': 0.0, 'right': 0.0},
4: {'left': 0.0, 'right': 0.0}, # Goal
}5.1 상태 3에서 오른쪽으로 이동
- 현재 상태: s = 3
- 행동: a = right
- 이동 결과:
3 → 4(G) - 보상: r = +10
- 다음 상태: s′ = 4
목표 상태 G(4)는 종료 상태라서 그 뒤로는 더 움직이지 않습니다.
즉, 다음 상태의 최대 Q값은 0으로 둡니다.
maxₐ′ Q(s′, a′) = 0학습률과 할인율을 다음과 같이 두면:
- α = 0.1
- γ = 0.9
target은:
target = r + γ maxₐ′ Q(s′, a′) = 10 + 0.9 × 0 = 10이전 Q값은 Q(3, right) = 0이었으므로:
Q(3, right) ← 0 + 0.1 × (10 − 0) = 1업데이트 후:
- 상태 3, 왼쪽: 0
- 상태 3, 오른쪽: 1
이제 에이전트 입장에서 “상태 3에서 오른쪽이 꽤 괜찮다”는 정보를 조금 배운 셈입니다.
이 과정을 여러 번 반복하면, 보상이 점점 앞쪽 상태(2, 1, 0)로도 전파됩니다.
6. Q-learning 코드 예제 – 보상이 뒤로 전파되는 과정 보기
위 1차원 예제를 코드로 구현해서, Q값이 어떻게 업데이트되고 보상이 어떻게 뒤쪽 상태로 전파되는지 볼 수 있습니다.
6.1 환경과 하이퍼파라미터
import random
states = [0, 1, 2, 3, 4]
goal_state = 4
actions = ['left', 'right']
alpha = 0.5 # 학습률
gamma = 0.9 # 할인율
epsilon = 0.2 # 탐험 확률 (ε-greedy)
episodes = 106.2 Q테이블 초기화
Q = {}
for s in states:
Q[s] = {}
for a in actions:
Q[s][a] = 0.06.3 행동 선택 – ε-greedy
def choose_action(state):
# ε 만큼은 랜덤 행동 (탐험)
if random.random() < epsilon:
return random.choice(actions)
# 나머지는 Q값이 큰 행동 선택 (exploitation)
else:
if Q[state]['left'] > Q[state]['right']:
return 'left'
elif Q[state]['left'] < Q[state]['right']:
return 'right'
else:
return random.choice(actions)6.4 환경 전이 함수
def step(state, action):
if action == 'left':
next_state = max(0, state - 1)
else: # 'right'
next_state = min(goal_state, state + 1)
if next_state == goal_state:
reward = 10
done = True
else:
reward = -1
done = False
return next_state, reward, done6.5 Q테이블 출력 함수
def print_q_table():
print('상태 | left | right')
print('-' * 32)
for s in states:
print(f'{s:>3} | {Q[s]["left"]:>7.2f} | {Q[s]["right"]:>7.2f}')
print('-' * 32)6.6 학습 루프
for episode in range(1, episodes + 1):
state = 0
done = False
print(f'---------- 에피소드 {episode} ----------')
while not done:
action = choose_action(state)
next_state, reward, done = step(state, action)
old_q = Q[state][action]
max_next_q = max(Q[next_state].values())
# goal 상태에서는 max_next_q = 0으로 처리
if next_state == goal_state:
max_next_q = 0
target = reward + gamma * max_next_q
new_q = old_q + alpha * (target - old_q)
Q[state][action] = new_q
print(f'현재 상태: {state}')
print(f'선택 행동: {action}')
print(f'다음 상태: {next_state}')
print(f'보상 r: {reward}')
print(f'이전 Q값: {old_q:.2f}')
print(f'target = r + gamma * maxQ(next) = {reward} + {gamma} * {max_next_q:.2f} = {target:.2f}')
print(f'새로운 Q값: {new_q:.2f}')
print('-' * 40)
state = next_state
print_q_table()
# 학습이 끝난 후, 각 상태에서의 최선 행동 출력
for s in states[:-1]:
best_action = max(Q[s], key=Q[s].get)
print(f'상태 {s} -> {best_action}')에피소드가 진행될수록:
- 목표에 가까운 상태(3, 2, 1, 0)의 오른쪽 행동 Q값이 점점 커지고,
- 잘못된 방향(왼쪽)의 Q값은 상대적으로 작아집니다.
결국 “상태 0에서 계속 오른쪽으로 가면 목표(G)에 도달한다”는 전략을 Q값만 보고도 스스로 찾아가게 됩니다.
[ 오늘의 정리 ]
- Q-learning의 포인트
- Q-learning은 각 상태–행동 쌍에 대한 가치(Q값)를 학습해, 점수가 가장 큰 행동을 선택하게 만드는 알고리즘입니다.
- Q값 업데이트는 “현재 보상 + 다음 상태의 최대 미래 가치”를 이용한 TD 업데이트 형태를 가집니다.
- ε-greedy를 통해 “가끔은 랜덤 탐험, 평소에는 Q값이 큰 행동”을 선택하면서, 탐험과 활용을 동시에 합니다.
- 단순한 1차원 예제에서도, 여러 에피소드를 반복하면 보상이 뒤쪽 상태로 전파되며 올바른 정책(오른쪽으로 이동)을 스스로 학습하는 모습을 확인할 수 있습니다.
'개념 정리실 > 강화학습' 카테고리의 다른 글
| Policy Gradient & REINFORCE – 정책 기반 에이전트 (1) | 2026.03.12 |
|---|---|
| DQN (Deep Q-Network) – Gym으로 CartPole 풀어보기 (0) | 2026.03.12 |
| Deep RL – 근사, 함수 근사, 신경망, 가치 기반·정책 기반 (0) | 2026.03.11 |
| TD Learning (Temporal Difference Learning) (0) | 2026.03.10 |
| 벨만 기대 방정식 (Bellman Expectation Equation) (0) | 2026.03.09 |